
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 도커
- Python
- 알고리즘
- 패치분할
- geojson
- GIS
- 3d데이터
- 귀여운고래
- osmnx
- 그리드분할
- geopandas
- 이미지빌드
- 데이터입수
- 컨테이너
- STL
- 파이썬
- 폴더조사
- graph
- pyvista
- python최단거리
- GCN
- 좌표거리
- 3d
- 지하철역좌표
- Set
- docker
- 동명이인찾기
- GNN
- 도커 레이어
- MESH
- Today
- Total
이것저것 기록
[python] NetworkX로 넷플릭스 유사 영화 추천 알고리즘 구현 본문
자료를 찾다가 캐글에서 꽤나 괜찮은 데이터를 발견했다.

위의 엑셀 파일을 열어보면 다음과 같다.
넷플릭스의 영화들에 대한 정보인데, 영화 제목, 감동, 제작국가, 상영연도, 러닝타임, 간단한 소개 등이 정리 되어 있는 엑셀이다.
이 정보들을 가지고 어떻게 추천 시스템을 만들 수 있을까, Academic/Adar 인덱스가 생각났다.
Academic/Adar는 그래프 이론에서 두 노드 간의 인접성을 정량화할 때 사용하는 것인데,
두 노드가 얼마나 가까운지 구하려면 두 노드가 서로 공유하고 있는 이웃의 개수를 살펴보면 된다는 것이다.

위의 식은 두 노드 x, y 에 대해서 두 노드가 가지고 있는 adjacent 노드들의 세트를 반환하는 함수이다.
쨌든 결론은! Academic/Adar와 클러스터링 기법을 사용해 간단히 추천 알고리즘을 구현해보려고 한다.
1. 필요 라이브러리
import networkx as nx
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import math as math
import time
import os
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
from sklearn.cluster import MiniBatchKMeans
2. 데이터 로드 및 정제
plt.style.use('seaborn')
plt.rcParams['figure.figsize'] = [14,14]
path = 'C:/Users/user/Desktop/tistory/'
os.chdir(path)
# 데이터 불러오기
df = pd.read_csv('netflix_titles.csv')
# 시간 정보 정제
df["date_added"] = pd.to_datetime(df['date_added'])
df['year'] = df['date_added'].dt.year
df['month'] = df['date_added'].dt.month
df['day'] = df['date_added'].dt.day
original_df = df.copy()
# "director, listed_in, cast and country" 컬럼을 리스트 형태로 저장
# NaN이면 빈 리스트가 생성됨
df['directors'] = df['director'].apply(lambda l: [] if pd.isna(l) else [i.strip() for i in l.split(",")])
df['categories'] = df['listed_in'].apply(lambda l: [] if pd.isna(l) else [i.strip() for i in l.split(",")])
df['actors'] = df['cast'].apply(lambda l: [] if pd.isna(l) else [i.strip() for i in l.split(",")])
df['countries'] = df['country'].apply(lambda l: [] if pd.isna(l) else [i.strip() for i in l.split(",")])
df.head()- strip() : string의 왼쪽과 오른쪽에서 제거
- 예를 들어 hello = " hello "
- hello.strip --> "hello"


3. TF-IDF 행렬 생성
start_time = time.time()
text_content = df['description']
vector = TfidfVectorizer(max_df=0.4, # drop words that occur in more than X percent of documents
min_df=1, # only use words that appear at least X times
stop_words='english', # remove stop words
lowercase=True, # Convert everything to lower case
use_idf=True, # Use idf
norm=u'l2', # Normalization
smooth_idf=True # Prevents divide-by-zero errors
)
tfidf = vector.fit_transform(text_content)TF-IDF는 여러 개의 문서가 있을 때, 각각의 문서의 내에 있는 단어들에 수치값을 주는 방법인데, 가중치가 적용되어있다.
TF-IDF를 계산하면 문서 내에 상대적으로 중요한 단어를 알 수 있다.
TF-IDF는 주로 문서 간 유사도를 측정하는데 사용하는데, 문서 간 유사도를 구하기 위해서는 코사인 유사도를 구하거나 Clustering을 사용하게 된다.
이 때 코사인 유사도나 Clustering을 하기 위해서는 단어들에 수치값이 부여되어 있어야 되기 때문에 TF-IDF를 계산하여 문서 내에 단어들에 수치값을 부여하게 된다.
4. K-means 클러스터링 적용
k = 200
kmeans = MiniBatchKMeans(n_clusters = k)
kmeans.fit(tfidf)
centers = kmeans.cluster_centers_.argsort()[:,::-1]
terms = vector.get_feature_names()
request_transform = vector.transform(df['description'])
# new column cluster based on the description
df['cluster'] = kmeans.predict(request_transform)
df['cluster'].value_counts().head()
5. 그래프 생성
노드의 종류는 다음과 같다
- Movies
- Person ( actor or director)
- Categorie
- Countrie
- Cluster (description)
- Sim(title) top 5 similar movies in the sense of the description
엣지는 다음과 같다
- ACTED_IN : relation between an actor and a movie
- CAT_IN : relation between a categrie and a movie
- DIRECTED : relation between a director and a movie
- COU_IN : relation between a country and a movie
- DESCRIPTION : relation between a cluster and a movie
- SIMILARITY in the sense of the description
def find_similar(tfidf_matrix, index, top_n = 5):
cosine_similarities = linear_kernel(tfidf_matrix[index:index+1], tfidf_matrix).flatten()
related_docs_indices = [i for i in cosine_similarities.argsort()[::-1] if i != index]
return [index for index in related_docs_indices][0:top_n]
G = nx.Graph(label="MOVIE")
start_time = time.time()
for i, rowi in df.iterrows():
if (i%1000==0):
print(" iter {} -- {} seconds --".format(i,time.time() - start_time))
G.add_node(rowi['title'],key=rowi['show_id'],label="MOVIE",mtype=rowi['type'],rating=rowi['rating'])
# G.add_node(rowi['cluster'],label="CLUSTER")
# G.add_edge(rowi['title'], rowi['cluster'], label="DESCRIPTION")
for element in rowi['actors']:
G.add_node(element,label="PERSON")
G.add_edge(rowi['title'], element, label="ACTED_IN")
for element in rowi['categories']:
G.add_node(element,label="CAT")
G.add_edge(rowi['title'], element, label="CAT_IN")
for element in rowi['directors']:
G.add_node(element,label="PERSON")
G.add_edge(rowi['title'], element, label="DIRECTED")
for element in rowi['countries']:
G.add_node(element,label="COU")
G.add_edge(rowi['title'], element, label="COU_IN")
indices = find_similar(tfidf, i, top_n = 5)
snode="Sim("+rowi['title'][:15].strip()+")"
G.add_node(snode,label="SIMILAR")
G.add_edge(rowi['title'], snode, label="SIMILARITY")
for element in indices:
G.add_edge(snode, df['title'].loc[element], label="SIMILARITY")
print(" finish -- {} seconds --".format(time.time() - start_time))
6. 두 개의 영화를 살펴보자
def get_all_adj_nodes(list_in):
sub_graph=set()
for m in list_in:
sub_graph.add(m)
for e in G.neighbors(m):
sub_graph.add(e)
return list(sub_graph)
def draw_sub_graph(sub_graph):
subgraph = G.subgraph(sub_graph)
colors=[]
for e in subgraph.nodes():
if G.nodes[e]['label']=="MOVIE":
colors.append('blue')
elif G.nodes[e]['label']=="PERSON":
colors.append('red')
elif G.nodes[e]['label']=="CAT":
colors.append('green')
elif G.nodes[e]['label']=="COU":
colors.append('yellow')
elif G.nodes[e]['label']=="SIMILAR":
colors.append('orange')
elif G.nodes[e]['label']=="CLUSTER":
colors.append('orange')
nx.draw(subgraph, with_labels=True, font_weight='bold',node_color=colors)
plt.show()
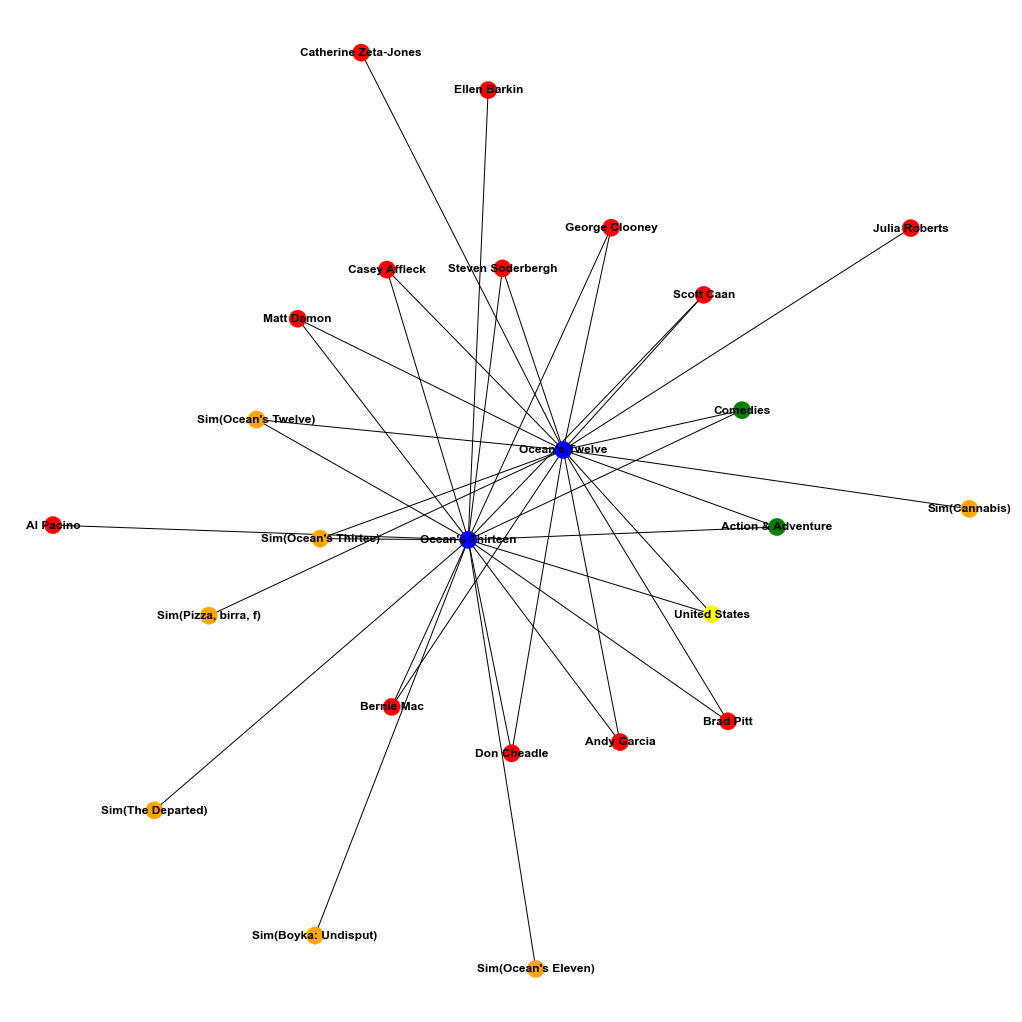
list_in=["Ocean's Twelve","Ocean's Thirteen"]
sub_graph = get_all_adj_nodes(list_in)
draw_sub_graph(sub_graph)위에서 만든 함수들과 그래프를 사용해서 "Ocean's Tweleve"와 "Ocean's Thirteen" 영화의 sub-graph를 살펴보려고 한다.
각각의 노드들은 종류에 맞게 색을 구분해주었다.
7. 추천 함수
def get_recommendation(root):
commons_dict = {}
for e in G.neighbors(root):
for e2 in G.neighbors(e):
if e2==root:
continue
if G.nodes[e2]['label']=="MOVIE":
commons = commons_dict.get(e2)
if commons==None:
commons_dict.update({e2 : [e]})
else:
commons.append(e)
commons_dict.update({e2 : commons})
movies=[]
weight=[]
for key, values in commons_dict.items():
w=0.0
for e in values:
w=w+1/math.log(G.degree(e))
movies.append(key)
weight.append(w)
result = pd.Series(data=np.array(weight),index=movies)
result.sort_values(inplace=True,ascending=False)
return result;추천 함수는 맨 위에서 설명한대로 이웃 노드를 가장 많이 공유하고 있는 노드들을 계산하는 방식이다.
예를 들어 내가 A라는 영화를 입력으로 주었으면,
그 A라는 영화(노드)과 이어진 다른 노드들에 가장 많이 이어져있는 영화 노드를 찾는 것이다.
8. 추천 받아보자
result = get_recommendation("Ocean's Twelve")
result2 = get_recommendation("Ocean's Thirteen")
result3 = get_recommendation("The Devil Inside")
result4 = get_recommendation("Stranger Things")
print("*"*40+"\n Recommendation for 'Ocean's Twelve'\n"+"*"*40)
print(result.head())
print("*"*40+"\n Recommendation for 'Ocean's Thirteen'\n"+"*"*40)
print(result2.head())
print("*"*40+"\n Recommendation for 'Belmonte'\n"+"*"*40)
print(result3.head())
print("*"*40+"\n Recommendation for 'Stranger Things'\n"+"*"*40)
print(result4.head())총 4번의 영화 추천을 받아봤다.
실행 결과

'코린이 > 실무를 위한 코딩 기록' 카테고리의 다른 글
| [python, GIS] OSMnx로 POI 데이터 추출 및 활용 (1) | 2020.12.16 |
|---|---|
| [python, GIS] geopy로 주소 간단하게 지오코딩 하는 방법 (5) | 2020.12.09 |
| [python, GIS] OSMnx로 도로 네트워크 단순화 (3) | 2020.12.07 |
| [python, GIS] OSMnx로 지역명을 geodataframe으로 불러오기 (0) | 2020.11.06 |
| [python, GIS] OSMnx를 이용한 최단경로탐색 및 계산 (0) | 2020.11.04 |



