
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 귀여운고래
- GIS
- 이미지빌드
- MESH
- 도커 레이어
- 파이썬
- graph
- 알고리즘
- GCN
- 좌표거리
- Set
- 그리드분할
- 폴더조사
- 컨테이너
- 데이터입수
- docker
- python최단거리
- pyvista
- 지하철역좌표
- 3d데이터
- 도커
- geojson
- STL
- 동명이인찾기
- GNN
- Python
- geopandas
- 3d
- 패치분할
- osmnx
- Today
- Total
이것저것 기록
[python/GIS] 세종시 생활권 별 최근린녹지공원까지의 평균거리 구하기 (geopandas, geojson, haversine) 본문
[python/GIS] 세종시 생활권 별 최근린녹지공원까지의 평균거리 구하기 (geopandas, geojson, haversine)
anweh 2021. 12. 28. 14:21오늘은 아주 예전에.. 데이터분석 경진대회에 사용했던 코드를 포스팅 하려고 한다.
사실 예전 코드를 다시 뜯어보는 것만큼 좋은 공부가 없는 것 같아, 요즘은 예전에 작성한 코드를 다시 읽어보고 있다.
물론 '왜 이렇게 비효율적으로 짠거지' 하는 부분도 있지만 '오, 진짜 기발하게 짰네'하는 부분도 있다.
어쨌든! 오늘 포스팅 할 내용은 세종시의 생활권 별 최근린 녹지공원까지의 평균 거리를 계산하는 코드다.
0. 필요 라이브러리
import os
import geopandas as gpd
from tqdm import tqdm
import haversine as hs
from haversine import Unit
import pandas as pd이 테스크에 사용하는 라이브러리는 위와 같다.
이중 geopandas, haversine은 유명한 라이브러리가 아니기 때문에 짧은 설명을 덧붙이고 넘어가자면..
- geopandas: 판다스의 gis버전이다. 데이터프레임 형태의 자료구조를 가지는데, 특이한 점은 지오메트리 정보도 저장할 수 있다는 점이다. geopandas는 설치 순서가 좀 까다롭다... (개열받음) shapely, fiona를 먼저 깔아줘야 하는데, 해당 라이브러리 설치 순서는 다음 블로그를 참고하면 된다. 나도 설치 순서 까먹어서 매번 이 블로그 참고함..ㅋㅋㅋㅋ (https://hansuho113.tistory.com/22)
- haversine: 거리 계산에 사용하는 라이브러리
1. 데이터 로드
''' Data Load '''
data_path = os.path.join(os.getcwd(), 'data')
gdf_31 = gpd.read_file(os.path.join(data_path, '31.세종시_법정경계(읍면동).geojson'))
gdf_23 = gpd.read_file(os.path.join(data_path, '23.세종시_도로명주소_건물.geojson'))
park_gdf = gpd.read_file(os.path.join(data_path, 'TL_SPOT_PARK.shp'), encoding='euc-kr')깃헙에 올려진 코드를 보면 알겠지만, 이 포스팅에 사용된 모든 데이터는 'data'라는 폴더 안에 정리해줬다.
지오메트리 정보를 포함하고 있는 데이터는 geopandas를 통해 불러왔다.
가끔 인코딩 정보를 명시해줘야 하는 데이터가 있다. (ex. park_gdf)
데이터에 대한 짧은 설명을 하고 넘어가자.
- gdf_31: 세종시 법정동 geojson데이터
- gdf_23: 세종시 내 건물 geojson데이터
- park_gdf: 전국 근린녹지공원 geojson데이터
아래에서 보다시피, park_gdf는 전국 대상 데이터이다. 나중에 필터 작업이 필요하다.


자 이제 위 데이터들 안에는 어떤 정보가 담겨있는지 '내용'을 확인해보자.


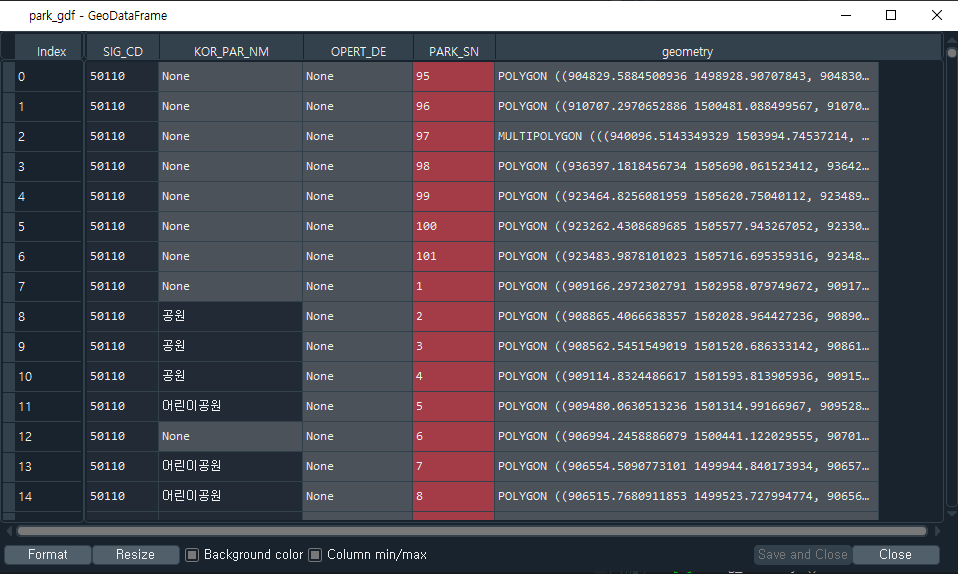
각각의 데이터가 갖고 있는 정보는 당연히 다르겠지만 유독 눈에 띄는게 있다.
바로 '좌표계'이다.
geometry컬럼을 보면, 공원 데이터만 좌표계가 다르다.
거리 계산을 위해선 나중에 좌표계 통일 작업이 필요할 거란 예상을 할 수 있다.
데이터 확인은 이쯤 하면 됐고, 이제 전처리로 넘어가보자.
2. 데이터 전처리
'''
<전처리 1>
생활권에 해당하는 면폴리곤만 남기기
- gdf_31은 세종시 전체를 포함하고 있는 데이터이므로, 1~6생활권 폴리곤만 추출해야함
'''
happy_city_gdf = gdf_31.loc[(gdf_31['EMD_KOR_NM'] == '집현동') | (gdf_31['EMD_KOR_NM'] == '반곡동') | (gdf_31['EMD_KOR_NM'] == '소담동') | (gdf_31['EMD_KOR_NM'] == '보람동') |
(gdf_31['EMD_KOR_NM'] == '대평동') | (gdf_31['EMD_KOR_NM'] == '가람동') | (gdf_31['EMD_KOR_NM'] == '한솔동') | (gdf_31['EMD_KOR_NM'] == '새롬동') | (gdf_31['EMD_KOR_NM'] == '나성동') |
(gdf_31['EMD_KOR_NM'] == '다정동') | (gdf_31['EMD_KOR_NM'] == '어진동') | (gdf_31['EMD_KOR_NM'] == '종촌동') | (gdf_31['EMD_KOR_NM'] == '고운동') | (gdf_31['EMD_KOR_NM'] == '도담동') |
(gdf_31['EMD_KOR_NM'] == '아름동') | (gdf_31['EMD_KOR_NM'] == '해밀동') | (gdf_31['EMD_KOR_NM'] == '산울동') | (gdf_31['EMD_KOR_NM'] == '합강동')]
# r(region)
r1 = ['고운동', '아름동', '종촌동', '도담동', '어진동'] # 1생활권
r2 = ['다정동', '새롬동', '한솔동', '나성동', '가람동'] # 2생활권
r3 = ['대평동', '보람동', '소담동'] # 3생활권
r4 = ['반곡동', '집현동'] # 4생활권
r5 = ['합강동'] # 5생활권
r6 = ['산울동', '해밀동'] # 6생활권
rs = []
for i in range(len(happy_city_gdf)):
cur_emd_cd = happy_city_gdf.iloc[i]['EMD_CD']
cur_emd_nm = happy_city_gdf.iloc[i]['EMD_KOR_NM']
if cur_emd_nm in r1:
rs.append('1생활권')
if cur_emd_nm in r2:
rs.append('2생활권')
if cur_emd_nm in r3:
rs.append('3생활권')
if cur_emd_nm in r4:
rs.append('4생활권')
if cur_emd_nm in r5:
rs.append('5생활권')
if cur_emd_nm in r6:
rs.append('6생활권')
happy_city_gdf['생활권'] = rs
rs.append('중앙녹지공원')
'''
<전처리 2>
생활권 별 건물 나누기
'''
gdf_23 = gdf_23.sample(frac=0.8).reset_index(drop=True) # 건물 개수가 너무 많아서 샘플링 했다.
# 1생활권
gdf_23_1 = gdf_23.loc[(gdf_23['EMD_CD'] == '111') | (gdf_23['EMD_CD'] == '112') | (gdf_23['EMD_CD'] == '113') | (gdf_23['EMD_CD'] == '114') | (gdf_23['EMD_CD'] == '110')]
# 2생활권
gdf_23_2 = gdf_23.loc[(gdf_23['EMD_CD'] == '106') | (gdf_23['EMD_CD'] == '107') | (gdf_23['EMD_CD'] == '108') | (gdf_23['EMD_CD'] == '109') | (gdf_23['EMD_CD'] == '105')]
# 3생활권
gdf_23_3 = gdf_23.loc[(gdf_23['EMD_CD'] == '102') | (gdf_23['EMD_CD'] == '103') | (gdf_23['EMD_CD'] == '104')]
# 4생활권
gdf_23_4 = gdf_23.loc[(gdf_23['EMD_CD'] == '101') | (gdf_23['EMD_CD'] == '118')]
# 5생활권
gdf_23_5 = gdf_23.loc[(gdf_23['EMD_CD'] == '117')]
# 6생활권
gdf_23_6 = gdf_23.loc[(gdf_23['EMD_CD'] == '115') | (gdf_23['EMD_CD'] == '116')]<전처리 1, 2>
gdf_31, 23을 보면 알 수 있듯이 세종시 전체에 대한 면폴리곤, 빌딩 폴리곤을 포함하고 있다.
내가 관심 있는 지역은 세종시 중에서도 '행복도시'에 해당하는 1 ~ 6생활권의 지역이기 때문에,
관심 지역에만 해당하는 폴리곤을 추출하기 위해 전처리를 진행했다.
gdf_31은 EMD_KOR_NM이라는 컬럼을 통해 행복도시만 골라낼 수 있다.
gdf_23은 EMD_CD라는 컬럼을 통해 행복도시만 골라내었다.
생활권을 가만 보면, 4생활권부터는 법정동 개수가 1,2,3생활권에 비해 적은 것을 알 수 있다.
이는 세종시 행복도시의 입주가 1,2,3생활권은 거의 완료된 데에 비해, 4생활권부터는 아직 개발 단계이기 때문이다.
여담인데 행복도시의 주택 구매가 있는 사람은 6생활권 입주가 끝나기 전에 계획하는 것이 좋을듯.. 나는 항상 눈여겨 보고 있음
'''
<전처리 3>
- 좌표계 통일 (5179 --> 4326)
- 세종시에 해당하는 녹지공간만 추출
'''
park_gdf.set_crs(epsg=5179, inplace=True, allow_override=True)
park_gdff = park_gdf.loc[(park_gdf['SIG_CD'] == '36110')] # 세종시의 시군구코드는 36110
park_gdff_ = park_gdff.to_crs(epsg=4326)세 번째 전처리는 전국 녹지공원 데이터인 park_gdf이다.
우선 좌표계를 gdf_31, gdf_23과 동일하게 맞춰주고,
시군구코드 컬럼(SIG_CD)을 사용하여 세종시 녹지공원만 추출했다.
3. 공원까지 거리 계산
'''
각 생활권 별로 ‘집에서’ 녹지공간까지의 접근성이 동일한가? -- happy_city_park, happy_city_park_dong
'''
print('각 생활권 별로 ‘집에서’ 녹지공간까지의 접근성이 동일한가? -- happy_city_park \n')
def assign_dong_value(dictionary, df_dong, attr):
df_dong[attr] = ''
for i in range(len(df_dong)):
cur_dong_nm = df_dong.iloc[i]['EMD_NM']
for k, v in dictionary.items():
if k == cur_dong_nm :
df_dong.at[i, attr] = v
return df_dong
def calculate_dist_to_park(gdf, park_gdff_):
bldg_2_park = []
for i in tqdm(range(len(gdf))):
# 해당 gdf(동)내 모든 빌딩에 대하여 중심점을 구함
cur_bldg_coord_x = gdf.iloc[i]['geometry'].centroid.xy[0][0]
cur_bldg_coord_y = gdf.iloc[i]['geometry'].centroid.xy[1][0]
park_dist_ls = []
min_d = 9999
for j in range(len(park_gdff_)):
# 세종시 내 모든 녹지공원의 중심점을 구함
cur_park_x = park_gdff_.iloc[j]['geometry'].centroid.xy[0][0]
cur_park_y = park_gdff_.iloc[j]['geometry'].centroid.xy[1][0]
meter_dist = hs.haversine((cur_park_y, cur_park_x),
(cur_bldg_coord_y, cur_bldg_coord_x),
unit=Unit.METERS)
if (meter_dist/1000.0) < 5:
polygon_type = park_gdff_.iloc[j]['geometry'].type
# park_gdf의 폴리곤이 두 종류로 이루어져 있어, 종류에 따라 다른 계산법을 적용해야함
if polygon_type == 'MultiPolygon':
for q in range(len(list(park_gdff_.iloc[j]['geometry']))):
polys = list(park_gdff_.iloc[j]['geometry'])
polyy = polys[q]
polyy_crd_length = len(polyy.exterior.coords)
for mc in range(polyy_crd_length):
ex_x = polyy.exterior.coords.xy[0][mc]
ex_y = polyy.exterior.coords.xy[1][mc]
dist1 = hs.haversine((ex_y, ex_x), (cur_bldg_coord_y, cur_bldg_coord_x), unit=Unit.METERS)
if dist1 < min_d:
min_d = dist1
park_dist_ls.append(min_d)
if polygon_type == 'Polygon':
simple_polygon = park_gdff_.iloc[j]['geometry'].simplify(0.05)
for c in range(len(simple_polygon.exterior.coords.xy[0])):
ex_xx = simple_polygon.exterior.coords.xy[0][c]
ex_yy = simple_polygon.exterior.coords.xy[1][c]
dist2 = hs.haversine((ex_yy, ex_xx), (cur_bldg_coord_y, cur_bldg_coord_x), unit=Unit.METERS)
if dist2 < min_d:
min_d = dist2
park_dist_ls.append(min_d)
else:
park_dist_ls.append(min_d)
bldg_2_park.append(min(park_dist_ls))
return bldg_2_park
def find_dong_nm(gdf, happy_city_gdf):
gdf['DONG_NM'] = ''
for i in range(len(gdf)):
cur_apt_poly = gdf.iloc[i]['geometry']
if cur_apt_poly == None :
continue
cur_apt_centroid = cur_apt_poly[0].centroid
for j in range(len(happy_city_gdf)):
cur_dong_poly = happy_city_gdf.iloc[j]['geometry'][0]
cur_dong_nm = happy_city_gdf.iloc[j]['EMD_KOR_NM']
if cur_dong_poly.contains(cur_apt_centroid):
gdf.at[i, 'DONG_NM'] = cur_dong_nm
return gdf
bldg_2_park_gdf_23_1 = calculate_dist_to_park(gdf_23_1, park_gdff_)
gdf_23_1 = gdf_23_1.reset_index()
gdf_23_1 = gdf_23_1.drop(['index'], axis=1)
gdf_23_1 = find_dong_nm(gdf_23_1, happy_city_gdf)
gdf_23_1['최근린녹지거리'] = bldg_2_park_gdf_23_1
bldg_2_park_gdf_23_2 = calculate_dist_to_park(gdf_23_2, park_gdff_)
gdf_23_2 = gdf_23_2.reset_index()
gdf_23_2 = gdf_23_2.drop(['index'], axis=1)
gdf_23_2 = find_dong_nm(gdf_23_2, happy_city_gdf)
gdf_23_2['최근린녹지거리'] = bldg_2_park_gdf_23_2
bldg_2_park_gdf_23_3 = calculate_dist_to_park(gdf_23_3, park_gdff_)
gdf_23_3 = gdf_23_3.reset_index()
gdf_23_3 = gdf_23_3.drop(['index'], axis=1)
gdf_23_3 = find_dong_nm(gdf_23_3, happy_city_gdf)
gdf_23_3['최근린녹지거리'] = bldg_2_park_gdf_23_3
bldg_2_park_gdf_23_4 = calculate_dist_to_park(gdf_23_4, park_gdff_)
gdf_23_4 = gdf_23_4.reset_index()
gdf_23_4 = gdf_23_4.drop(['index'], axis=1)
gdf_23_4 = find_dong_nm(gdf_23_4, happy_city_gdf)
for i in range(len(gdf_23_4)):
cur_ = gdf_23_4.iloc[i]['EMD_CD']
if cur_ == '101':
gdf_23_4.at[i, 'DONG_NM'] = '반곡동'
gdf_23_4['최근린녹지거리'] = bldg_2_park_gdf_23_4
bldg_2_park_gdf_23_5 = calculate_dist_to_park(gdf_23_5, park_gdff_)
gdf_23_5 = gdf_23_5.reset_index()
gdf_23_5 = gdf_23_5.drop(['index'], axis=1)
gdf_23_5 = find_dong_nm(gdf_23_5, happy_city_gdf)
gdf_23_5['최근린녹지거리'] = bldg_2_park_gdf_23_5
bldg_2_park_gdf_23_6 = calculate_dist_to_park(gdf_23_6, park_gdff_)
gdf_23_6 = gdf_23_6.reset_index()
gdf_23_6 = gdf_23_6.drop(['index'], axis=1)
gdf_23_6 = find_dong_nm(gdf_23_6, happy_city_gdf)
gdf_23_6['최근린녹지거리'] = bldg_2_park_gdf_23_6
happy_city_park = {'1생활권': gdf_23_1['최근린녹지거리'].sum()/len(gdf_23_1),
'2생활권': gdf_23_2['최근린녹지거리'].sum()/len(gdf_23_2),
'3생활권': gdf_23_3['최근린녹지거리'].sum()/len(gdf_23_3),
'4생활권': gdf_23_4['최근린녹지거리'].sum()/len(gdf_23_4),
'5생활권': gdf_23_5['최근린녹지거리'].sum()/len(gdf_23_5),
'6생활권': gdf_23_6['최근린녹지거리'].sum()/len(gdf_23_6)}
happy_city_park_dong = {'고운동': gdf_23_1.loc[gdf_23_1['DONG_NM']=='고운동']['최근린녹지거리'].sum()/len(gdf_23_1[gdf_23_1['DONG_NM']=='고운동']),
'아름동': gdf_23_1.loc[gdf_23_1['DONG_NM']=='아름동']['최근린녹지거리'].sum()/len(gdf_23_1[gdf_23_1['DONG_NM']=='아름동']),
'종촌동': gdf_23_1.loc[gdf_23_1['DONG_NM']=='종촌동']['최근린녹지거리'].sum()/len(gdf_23_1[gdf_23_1['DONG_NM']=='종촌동']),
'도담동': gdf_23_1.loc[gdf_23_1['DONG_NM']=='도담동']['최근린녹지거리'].sum()/len(gdf_23_1[gdf_23_1['DONG_NM']=='도담동']),
'어진동': gdf_23_1.loc[gdf_23_1['DONG_NM']=='고운동']['최근린녹지거리'].sum()/len(gdf_23_1[gdf_23_1['DONG_NM']=='어진동']),
'다정동': gdf_23_2.loc[gdf_23_2['DONG_NM']=='다정동']['최근린녹지거리'].sum()/len(gdf_23_2[gdf_23_2['DONG_NM']=='다정동']),
'새롬동': gdf_23_2.loc[gdf_23_2['DONG_NM']=='새롬동']['최근린녹지거리'].sum()/len(gdf_23_2[gdf_23_2['DONG_NM']=='새롬동']),
'한솔동': gdf_23_2.loc[gdf_23_2['DONG_NM']=='한솔동']['최근린녹지거리'].sum()/len(gdf_23_2[gdf_23_2['DONG_NM']=='한솔동']),
'나성동': gdf_23_2.loc[gdf_23_2['DONG_NM']=='나성동']['최근린녹지거리'].sum()/len(gdf_23_2[gdf_23_2['DONG_NM']=='나성동']),
'가람동': gdf_23_2.loc[gdf_23_2['DONG_NM']=='가람동']['최근린녹지거리'].sum()/len(gdf_23_2[gdf_23_2['DONG_NM']=='가람동']),
'대평동': gdf_23_3.loc[gdf_23_3['DONG_NM']=='대평동']['최근린녹지거리'].sum()/len(gdf_23_3[gdf_23_3['DONG_NM']=='대평동']),
'보람동': gdf_23_3.loc[gdf_23_3['DONG_NM']=='보람동']['최근린녹지거리'].sum()/len(gdf_23_3[gdf_23_3['DONG_NM']=='보람동']),
'소담동': gdf_23_3.loc[gdf_23_3['DONG_NM']=='소담동']['최근린녹지거리'].sum()/len(gdf_23_3[gdf_23_3['DONG_NM']=='소담동']),
'반곡동': gdf_23_4.loc[gdf_23_4['DONG_NM']=='반곡동']['최근린녹지거리'].sum()/len(gdf_23_4[gdf_23_4['DONG_NM']=='반곡동']),
'집현동': gdf_23_4.loc[gdf_23_4['DONG_NM']=='집현동']['최근린녹지거리'].sum()/len(gdf_23_4[gdf_23_4['DONG_NM']=='집현동']),
'합강동': gdf_23_5.loc[gdf_23_5['DONG_NM']=='합강동']['최근린녹지거리'].sum()/len(gdf_23_5[gdf_23_5['DONG_NM']=='합강동']),
'산울동': gdf_23_6.loc[gdf_23_6['DONG_NM']=='산울동']['최근린녹지거리'].sum()/len(gdf_23_6[gdf_23_6['DONG_NM']=='산울동']),
'해밀동': gdf_23_6.loc[gdf_23_6['DONG_NM']=='해밀동']['최근린녹지거리'].sum()/len(gdf_23_6[gdf_23_6['DONG_NM']=='해밀동'])}
dong_dict = {'고운동': [0, 0], '아름동': [0, 0], '종촌동': [0, 0], '도담동': [0, 0], '어진동': [0, 0], '다정동': [0, 0],
'새롬동': [0, 0], '한솔동': [0, 0], '나성동': [0, 0], '가람동': [0, 0], '대평동': [0, 0], '보람동': [0, 0],
'소담동': [0, 0], '반곡동': [0, 0], '집현동': [0, 0], '합강동': [0, 0], '산울동': [0, 0], '해밀동': [0, 0]}
df_dong = pd.DataFrame(dong_dict.keys(), columns=['EMD_NM'])
df_dong = assign_dong_value(happy_city_park_dong, df_dong, '최근린녹지까지의평균거리')거리 계산 프로세스를 정의하자면,
- 1. gdf_23_1 ~ gdf_23_6에 대하여 (행복도시의 각 생활권에 대하여)
- 2. 각 생활권 내 모든 주거용 건물의 중심점(cur_bldg_coord_x, cur_bldg_coord_y)으로부터
- 최근린 녹지공원 중심점(cur_park_x, cur_park_y)을 찾는다.
- 3. 최근린 녹지공원 폴리곤의 바운더리 포인트 중, 주거용 건물에서 가장 가까운 포인트(ex_x, ex_y)를 찾는다.
- 4. 거리(dist1, dist2)를 계산하여 bldg_2_park에 저장한다.
- 5. bldg_2_park에 저장된 거리를 모두 합하여, 해당 생활권 내 주거용 건물의 개수로 나누어 '평균'을 구한다.
- 6. 각 생활권을 동(df_dong)으로 분류하여 정리한다.
실행 결과:

4. FYI
사실 아주 예전에 짜뒀던 코드라 그리 깔끔하지 못하다. (데이터가 엉망인 탓도 있다.)
코드와 데이터는 모두 깃헙에 업로드 하였으니, 직접 다운 받아 디버깅 하며 스텝바이스텝 따라가 보는 편이 가장 이해가 빠를 것 같다!
https://github.com/henewsuh/sejong_find_near_park
GitHub - henewsuh/sejong_find_near_park: first_commit
first_commit. Contribute to henewsuh/sejong_find_near_park development by creating an account on GitHub.
github.com
'코린이 > 실무를 위한 코딩 기록' 카테고리의 다른 글
| [python/GIS] QGIS 없이 파이썬만 사용해 최단거리 구하기 (OSMnx, geopandas) (5) | 2023.01.16 |
|---|---|
| [python] libpng warning: iCCP: known incorrect sRGB profile 문제 해결 (0) | 2021.12.13 |
| [python] STL to VTK / VTK to STL (0) | 2021.12.13 |
| [python] 3D Mesh (.stl) 데이터 그리드(패치) 분할하기 (2) | 2021.07.01 |
| [python] 폴더/하위 폴더의 파일 목록 출력 (0) | 2021.06.04 |



