
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 알고리즘
- 도커 레이어
- osmnx
- graph
- 데이터입수
- 그리드분할
- MESH
- 폴더조사
- 좌표거리
- python최단거리
- GIS
- 파이썬
- Python
- Set
- 컨테이너
- 3d데이터
- GNN
- geopandas
- STL
- 귀여운고래
- 3d
- 패치분할
- GCN
- 도커
- geojson
- pyvista
- 동명이인찾기
- 지하철역좌표
- docker
- 이미지빌드
- Today
- Total
이것저것 기록
[graph] 그래프 임베딩에 대한 기록 (1) 본문
1. 그래프 임베딩이란
-
Graph embeddings are the transformation of properties of a graph to a vector or a set of vectors.
-
그래프 구조의 데이터의 차원을 축소하여 low-dimention 벡터로 표현하는 것
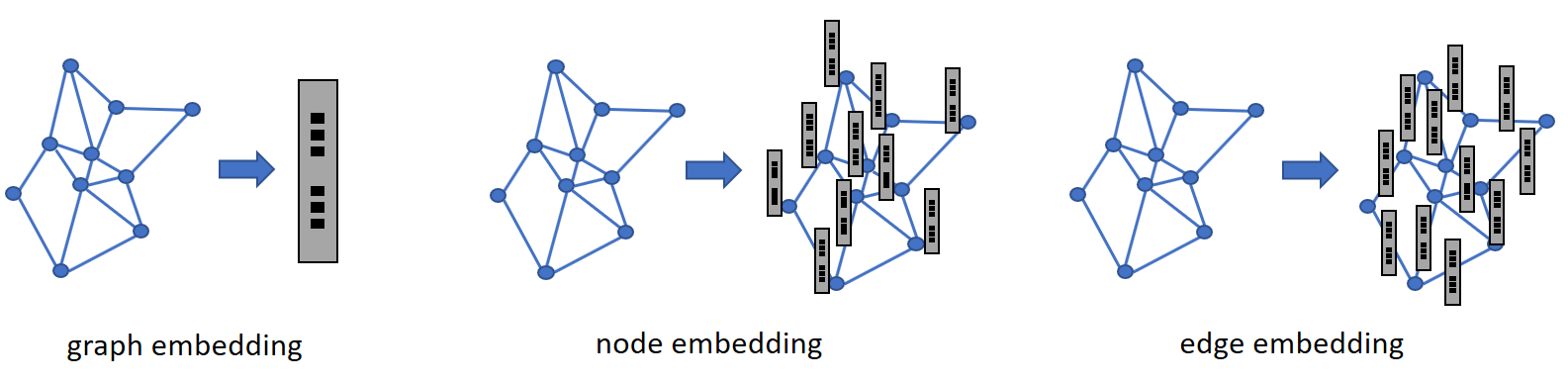
2. 그래프 임베딩의 이유
-
ML on graphs is limited
-
Embeddings are a compressed representation
-
Vector operations are simpler and faster
-
>> 그래프는 이미지나 시계열과 같이 정형적인 형태의 데이터가 아니다. 때문에 그래프 구조를 가지고 그래프 분류든 예측이든, ML을 활용하여 뭔가를 하기엔 매우 불편하다. 예를 들어보자. CNN의 학습 데이터로 흔히 사용되는 이미지는 데이터들간 크기가 모두 동일하다. 그러나 그래프는? 페이스북 사용자의 친구 그래프를 가지고 뭔가 하고 싶다고 가정했을 때, 개개인의 친구 (노드) 수는 모두 다르고, 상대에 따라 그 관계 (엣지)도 다를 것이다. 이렇듯 그래프로 나타내는 데이터들은 이미지나 시계열과 같이 정형적이지 않다. 그렇기 때문에 요 그래프 데이터로 뭔가를 하고 싶다면, 복잡하고 제각각의 그래프를 하나의 일관된 형태로 만들어야한다.
3. 그래프 임베딩 방법론들
[1] Graph Kernels and handcrafted features
-
Evaluate the similarity (kernel value) between a pair of graphs G and G' by recursively decomposing them into atomic substructures.
-
Define a similarity function over the substructures.
-
e.g. random walks, shortest paths, graphlets
-
한계점:
-
Many of them do not provide explicit graph embeddings.
-
The substructures (walk, path, etc..) leveraged by these kernels are 'handcrafted.' --> determined manually
-
[2] Learning structure embeddings
-
GCN, GAT과 같이 neighbor 구조를 AGGREGATE 하여 노드를 임베딩하는 기법들
-
한계점:
-
These substructure (nodes, paths, subgraphs) representation learning approaches are incapable of learning representation of entire graph --> cannot be used for tasks such as graph classification.
-
[3] Learning task-specific graph embeddings
-
Learn embeddings of entire graphs
-
e.g. PATCHY-SAN
-
한계점:
-
라벨링 개수에 성능이 좌우되기 때문에 라벨링이 매우 많이 필요하다
-
[4] graph2vec (2017)
-
Unsupervised representation learning
-
Task-agnostic embeddings
-
Data-driven embeddings
-
Capture the generic characteristics of entire graphs in the form of their embeddings
-
View an entire graph as a document, and the rooted subgraphs around every node in the graph as words that compose the document and extend document embedding neural networks to learn the representation of the entire graph --> 전체 그래프를 하나의 문단으로 보고 subgraph를 하나의 단어(그래프를 이루는 가장 작은 단위)로 보는 것이다.
-
이 논문에서는 Skipgram Model을 사용했는데, 이 모델의 목적은 특정 문단(=그래프)의 임베딩이 그 문단에 등장하는 단어들(=subgraphs)의 임베딩과 비슷해지는 것이다. 즉 유사한 단어(=subgraphs)을 많이 포함하고 있는 문단들끼리 유사한 임베딩을 갖게 될 것이다.
-
아마도 졸업 논문에 그래프 임베딩을 사용하게 될 것 같은데... 나는 내가 만들어낼 그래프 임베딩의 단어와 문단의 기준을 잘 정해봐야할 것 같다.
-
-
graph2vec의 근간이 된 doc2vec의 수식을 살펴보자.
-
doc2vec은 어떤 문단 d를 어떻게 임베딩할 것인가에 대한 함수이다. 어떤 문단 d는 d를 이루고 있는 w의 sequence로 나타낼 수 있다. 그리고 이를 임베딩하는 skipgram model은 (4)수식을 maximize하는 방향으로 학습한다.
-
(4)수식: 특정 문단의 임베딩이 그 문단에 등장하는 임베딩과 비슷해지는 것. 분모는 모든 문단들의 단어를 의미하고, 분자는 해당 문단의 단어들을 의미한다.
-

참고 링크:
'Data Science > ML & DL' 카테고리의 다른 글
| [python] 데이터 유사성 측정방법 (0) | 2021.04.12 |
|---|---|
| [graph] 그래프 임베딩에 대한 기록 (2) (0) | 2021.01.06 |
| [graph] graphSAGE의 embedding generation algorithm에 대한 기록 (0) | 2021.01.05 |
| [graph] graph pooling에 대한 기록 (0) | 2021.01.01 |
| [graph] GNN의 set aggregator에 대한 기록 (0) | 2021.01.01 |



