
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- geojson
- 지하철역좌표
- 귀여운고래
- 좌표거리
- 컨테이너
- python최단거리
- STL
- 동명이인찾기
- 3d데이터
- 알고리즘
- docker
- GNN
- 도커
- 이미지빌드
- geopandas
- Python
- pyvista
- osmnx
- 그리드분할
- GIS
- 3d
- graph
- MESH
- 패치분할
- Set
- 폴더조사
- 도커 레이어
- 데이터입수
- 파이썬
- GCN
- Today
- Total
이것저것 기록
[python, ML] scikit-learn을 사용하여 학습/테스트 데이터 전처리하기 본문

한동안 데이터 분석 쪽을 엄청 파다가, 요즘은 머신러닝을 공부하고 있다.
머신러닝은 이미 엄청나게 성능이 좋은 프레임워크가 많이 개발 돼 있고, 또 이것들이 사용하기 편하게 라이브러리로 전부 제공하고 있다. (그래서 나는 생각보다 쉽게 쉽게 배우고 있다. 적어도 딥러닝 처음 배울 때만큼 막막하진 않은 듯?)
머신러닝 모델은 사이킷런에서 그냥 함수 갖다쓰듯이 사용하면 되기 때문에,
사실 머신러닝을 적용할 때에 가장 중요한 부분은 '데이터 전처리'인 것 같다.
그래서 오늘은 내가 강의를 들으면서 배운 머신러닝 모델에 데이터를 넣기 전, 전처리를 도와주는 함수와 내용들을 포스팅 해보려고 한다.
내 돈 주고 공부 중인데 까먹을까봐 이렇게 기록해두려는 목적도 있고...ㅋㅋㅎ
공부하면서 작성한 코드와 샘플 데이터는 깃헙에 올려놨으니 참고해주세요~~
github.com/henewsuh/data_preprocessing_using_scikit_learn
henewsuh/data_preprocessing_using_scikit_learn
scikit-learen을 활용한 데이터 전처리 for ML. Contribute to henewsuh/data_preprocessing_using_scikit_learn development by creating an account on GitHub.
github.com
1. 라이브러리 및 데이터 불러오기
import pandas as pd
import os
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
df = pd.read_csv('high_diamond_ranked_10min.csv')
df_head = df.head() 언제나처럼 가장 먼저 사용할 라이브러리들과, pd.read_csv()를 사용하여 데이터를 불러온다.
캐글에서 제공하는 데이터는 컬럼값이 거의 영어로 작성 돼 있기 때문에 인코딩을 신경 쓸 필요는 없지만,
컬럼명이 한글로 표기 돼 있는 경우는 pd.read_csv(encoding='인코딩스타일') 이렇게 인자를 입력해야 한다.
보통은 cp949나 utf-8을 입력하면 된다.
2. 범주형, 수치형 데이터 분리
df.drop(['gameId', 'redFirstBlood', 'redKills', 'redDeaths',
'redTotalGold', 'redTotalExperience', 'redGoldDiff',
'redExperienceDiff'], axis=1, inplace=True)
X_num = df[['blueWardsPlaced', 'blueWardsDestroyed',
'blueKills', 'blueDeaths', 'blueAssists', 'blueEliteMonsters',
'blueTowersDestroyed', 'blueTotalGold',
'blueAvgLevel', 'blueTotalExperience', 'blueTotalMinionsKilled',
'blueTotalJungleMinionsKilled', 'blueGoldDiff', 'blueExperienceDiff',
'blueCSPerMin', 'blueGoldPerMin', 'redWardsPlaced', 'redWardsDestroyed',
'redAssists', 'redEliteMonsters', 'redTowersDestroyed', 'redAvgLevel', 'redTotalMinionsKilled',
'redTotalJungleMinionsKilled', 'redCSPerMin', 'redGoldPerMin']]
X_cat = df[['blueFirstBlood', 'blueDragons', 'blueHeralds', 'redDragons', 'redHeralds']]
y = df['blueWins']첫번째 줄에서 8개의 컬럼을 드롭해준 이유는, 해당 컬럼들이 피쳐로 사용하기에 부적절하기 때문이다.
예를 들어 gameId는 해당 게임의 고유 id이기 때문에 패턴을 반복할 수 있는 피쳐가 아니다.
다음 red + 어쩌구는 blue + 어쩌구와 상호보완적인 피쳐이기 때문에 중복해서 넣을 필요가 없다.
데이터 프레임에서 특정 열을 제거해주기 위해선 axis=1을 꼭 써줘야한다. 디폴트가 axis=0이기에 저렇게 안써주면 행이 전부 지워져버린다;;
X_num = df[['컬럼명', '컬럼명', '컬럼명']] <-- 이렇게 [[ ]] 를 사용한 이유는 [ ] 를 했을 경우엔 해당 컬럼값이 Series로 들어가기 때문에 꼭 [[ ]] 으로 써줘야한다.
3. 수치형 데이터 스케일링
scaler = StandardScaler()
scaler.fit(X_num)
X_scaled = scaler.transform(X_num)
X_scaled = pd.DataFrame(X_scaled, index=X_num.index, columns=X_num.columns)
X = pd.concat([X_scaled, X_cat], axis=1)데이터 모델링을 위해선 스케일링이 필수적이다.
스케일링은 다차원 값들을 분석에 용이하게 변경하고, 자료의 오버플로우 및 언더플로우를 방지한다.
특히 k-means 클러스터링 등 거리 기반 모델링에서는 스케일링이 더욱 중요해진다.
사이킷런에서 제공하는 스케일링은 정말 여러 개가 있는데, 그 중 대표는 다음 네 개이다.
- StandardScaler: 기본 스케일, 평균과 표준편차 사용
- MinMaxScaler: 최대값이 1, 최소값이 0이 되도록 스케일링
- MaxAbsScaler: 최대절대값이 1, 최소절대값이 0이 되도록 스케일링
- RobustScaler: 중앙값과 IQR을 사용. 아웃라이어의 영향을 최소화함
4. 범주형 데이터 수치로 바꾸어 표현하기 (get_dummies)
X_catt = pd.get_dummies(X_cat, columns=['blueFirstBlood'], drop_first=True)사실 이 데이터에서는 트랜스폼 해야할 범주형 데이터가 없지만, 예시로 작성해봤다.
범주형 데이터, 예를 들어 '성별'이라는 컬럼에 '남자', '여자'라는 값이 있을 때, 이것들은 반드시 숫자로 변환해주어야 한다. (문자열 데이터는 모델링할 수 없음..)
그래서 get_dummies를 사용하여 원핫인코딩을 진행해주어야한다.
5. 학습데이터와 테스트데이터 분리하기
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)학습 : 테스트 = 7 : 3 으로 분리해주었다.
test_size를 조절하면 다른 비율로도 분리가 가능함!
train_test_split()함수를 사용하면 이렇게 손쉽게 한 줄로 분리가 가능하다.
6. 분류 모델 학습하기
model_lr = LogisticRegression(max_iter=10000)
model_lr.fit(X_train, y_train)모델 학습을 위해서는 우선 model_lr에 사용하고자 하는 모델과 에폭을 설정해준다.
확실히 머신러닝은 딥러닝에 비해 모델을 정의하고, 모델을 사용하는 게 쉬운 것 같다.
정의한 모델에 .fit( ) 을 사용해서 아까 train_test_split( )에서 자른 X_train과 y_train을 넣어 학습시켜주자.
7. 모델 학습 결과 평가하기
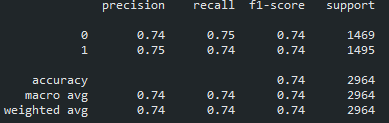
pred = model_lr.predict(X_test)
print(classification_report(y_test, pred))학습한 모델에 .predict( ) 을 사용하여 X_test를 넣어서 예측값을 뽑는다.
그리고 이렇게 예측한 값과, 실제 y 값 (y_test)가 얼마나 맞는지 확인하기 위해서 classification_report( )로 테스트를 진행한다.
'Data Science > ML & DL' 카테고리의 다른 글
| [python] 데이터 유사성 측정방법 (0) | 2021.04.12 |
|---|---|
| [graph] 그래프 임베딩에 대한 기록 (2) (0) | 2021.01.06 |
| [graph] 그래프 임베딩에 대한 기록 (1) (0) | 2021.01.06 |
| [graph] graphSAGE의 embedding generation algorithm에 대한 기록 (0) | 2021.01.05 |
| [graph] graph pooling에 대한 기록 (0) | 2021.01.01 |



